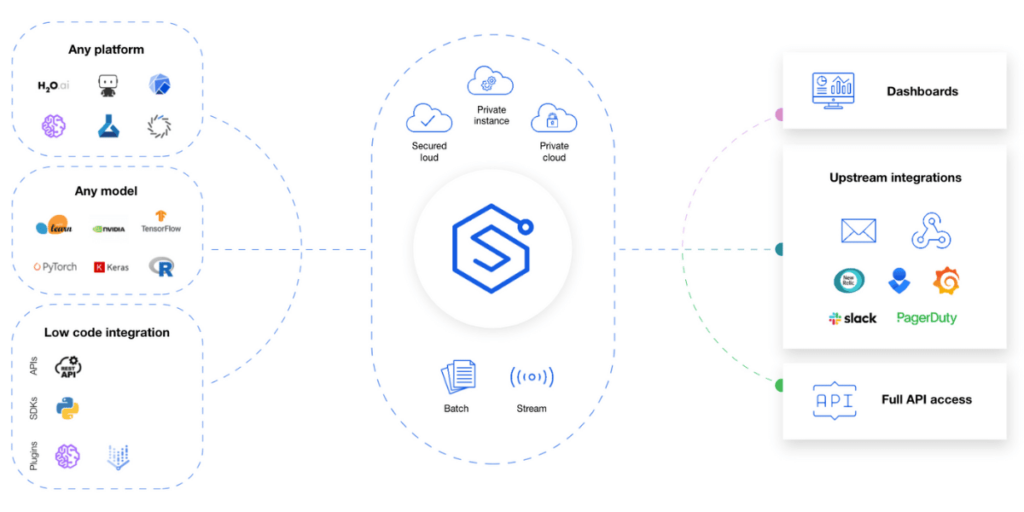
Understanding ML monitoring debt

This article was originally published on Towards Data Science and is part of an ongoing series exploring the topic of ML monitoring debt, how to identify it, and best practices to manage and mitigate its impact
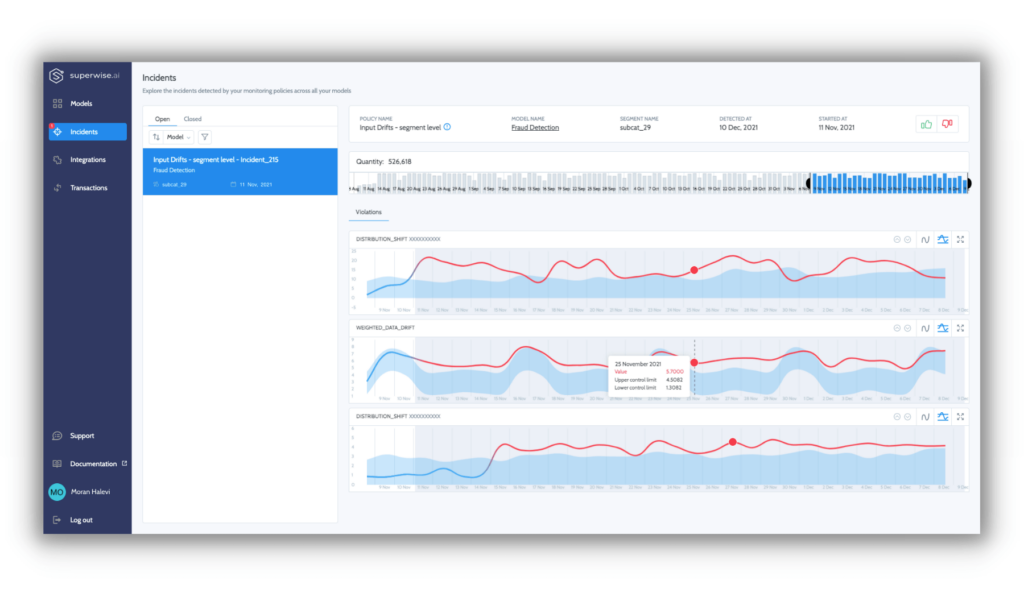
We’re all familiar with technical debt in software engineering, and at this point, hidden technical debt in ML systems is practically dogma. But what is ML monitoring debt? ML monitoring debt is when model monitoring is overwhelmed by the scale of the ML systems that it’s meant to monitor. Leaving practitioners to literally search for the proverbial needle in a haystack or, worse, hit ‘delete all’ on alerts.
ML monitoring is nowhere near as clear-cut as traditional APM monitoring. Not only are there no absolute truths when it comes to metrics and benchmarks, but models are not subject to economies of scale. It’s easy to spin up a new Kubernetes cluster, and the cluster will be subject to the same performance metrics, benchmarks, thresholds, and KPIs as its predecessors. But when you deploy a new model, even if it’s a pre-existing model and there has been no change to the artifact, it’s practically guaranteed that your references will be different. That means that you’re incurring debt for every model that you deploy to production and monitor.
What is a bad performance level? 80% accuracy? 60% accuracy?
Multiple factors need to be considered to identify a good/bad performance level, and the bottom line will be different depending on each model’s use case, segments, and of course, data. In this post, we’ll explain the debt dimensions of ML model monitoring by using “The four V’s of Big Data” framework, which lends itself surprisingly well for this comparison.
1. Veracity
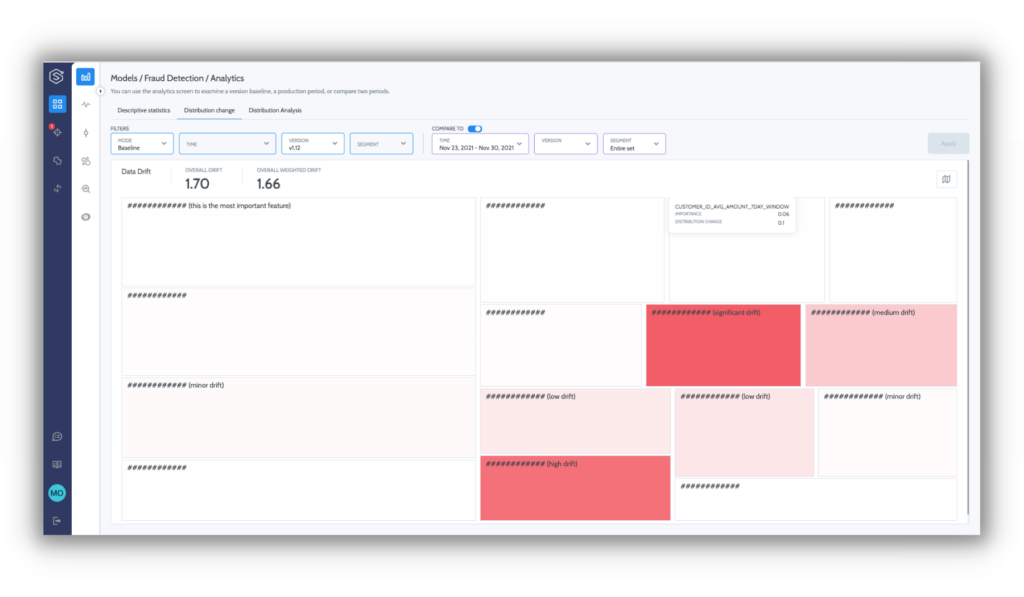
High dimensionality
Measuring and monitoring a data-driven process dependent on 2–3 elements is reasonably straightforward. But ML is all about utilizing large amounts of data sources and entities to locate underlying, predictable patterns. Depending on the problem and dependent data, you could be looking at dozens of features or even hundreds and thousands of features, each one of which should be monitored independently.
Model metrics
ML is a stochastic data-oriented world combined from multiple different pipelines in production. This means that a host of metrics and elements need to be tracked and monitored for each entity, such as feature mean, std, and missing values for numerical elements and cardinality levels, entropy, and more for categorical elements. Comprehensive model metrics go beyond features, data, and pipeline integrity to provide quantifiable metrics to analyze the relative quality of model inputs and outputs.
Chip Huyen recently published a comprehensive list of model metrics covering the entire model life cycle that’s worth checking out.
2. Volume
Volume in ML monitoring needs to be analyzed on two dimensions: Throughput and granularity
Throughput
Models usually work on large amounts of data to automate a decision process. This poses an engineering challenge to monitor and observe the distribution and behavior of your dataset. A monitoring solution needs to detect data quality and performance issues in minutes in parallel to analyzing huge streams of data over time.
Resolution of data
To detect things on subpopulation levels requires the ability to slice data by segments, but it’s also an analytical challenge. The nature of data and model performance may vary dramatically for the same metric under different subpopulations.

For example, a missing value indicator on a feature called “Age” may usually be 20% on the overall population, but for a specific channel, say Facebook, the value may be optional and, in 60% of cases, is a missing value where for all other subpopulations it’s a missing value in only 0.5% of the cases.
A high-level view will give you only so much information, particularly regarding subpopulations and detailed resolutions critical to support business needs and decisions. Macro events that impact entire datasets or populations are things that everybody knows to look out for and are usually detected relatively quickly.
But this means that the engineering and analytical challenge of detecting issues in a huge stream of data is now multiplied by the number of different segments you need to monitor.
3. Velocity
Models serve the automation of business processes at different velocities, from batch daily weekly prediction and up to real-time ms decisions on a high scale. Depending on your use cases, you’ll need to be able to support varying types of velocities. Still, like with volume, velocity has an additional dimension to contend with, pipeline velocity. Looking at the entire inference flow as a pipeline for continuous improvement. In order to move fast without breaking things, you’ll need to reincorporate delayed feedback into your ML decision-making processes.
In some use cases, such as an Ad-tech real-time bidding algorithm, we will want to monitor for weekly effects as we need to be able to detect data quality or performance issues in a manner of minutes to avoid business catastrophes.
4. Variety
Last but not least, we come to variety. A successful model with business ROI spans more models. Once you get past that first model hurdle and prove ML’s positive impact on business outcomes, both your team and your business will want to replicate this success and scale it. There are three ways to scale models, and they are not mutually exclusive to each other.
Versions
ML is an iterative process, and versions are how we do it. The real world is not static, so pipelines and models must be optimized continuously. Versions are constantly created for the same existing models, but each version is actually a totally different model instance that may have different features or even different baselines.
Use case scale
Adding a use case to your arsenal means you’re essentially restarting the entire MLOps cycle from scratch. You can carry over many things, especially when it comes to feature engineering, but when you deploy to production, you’ll have a new set and scale of model metrics to monitor. In addition to the technical side of ML monitoring, models drive business processes, and each process is different from the others. For the same loan approval model, risk and compliance teams may be concerned about potential biases due to regulatory concerns, business ops want to be the first to know if the model suddenly decides to decline loans across the board, ML engineers need to know about integrity and pipeline issues, and data science teams may be interested in slow drifts in model predictions. The point is that it’s multidisciplinary, and your stakeholders are interested in different aspects of the ML decision-making process. With a new process, you need to make sure that you’re delivering value fast.
Multi-tenancy scale
Multi-tenancy has exponential scale capacity. Deciding to deploy a model across multiple tenets is used when a tenant equals a population in its own right. For example, deploying a learning process that detects potential customer churn, but on each country separately (tenant in this case). The result is a standalone model per country.

Making a decision like this can take you from a single fraud model to hundreds of fraud models overnight. And while they may share the same set of metrics, expected values, and behaviors will vary.
What we’ve learned about model monitoring debt
On the surface of things, model monitoring can seem deceptively straightforward. To be fair, with one or two models, it is feasible to monitor ML manually if you’re willing to invest the resources. But in ML engineering, just like software engineering, everything is a question of the debt and scale. Is it worth taking on and paying down later? Model monitoring is not a simple task, nor is it straightforward both from a technological and process perspective, and as you scale, so does the difficulty of managing ML monitoring.
The 4 V’s illustrate why model monitoring is complex, and as an exercise in quantifying this problem, let’s think about the following numbers:
| #models | 1 | 15 | 100 |
| Avg features/model | 100 | 100 | 100 |
| Avg segments/model | 10 | 10 | 10 |
| Avg metrics/features + outputs + labels | 5 | 5 | 5 |
| Data points | 5,000 | 75,000 | 500,000 |
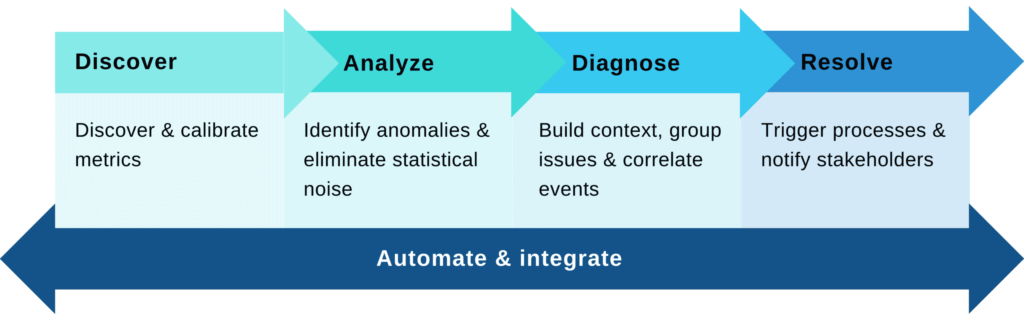
Now that we’ve quantified the inherent scale problem of ML monitoring and what causes it, the next step is to identify debt. The following parts of this series will deal with identifying debt indicators and best practices to manage and overcome model monitoring debt.
Stay tuned!
Want to see how Superwise can help you stay on top of monitoring debt?
Request a demo to see how!